Dangers of OpenCSV beans streaming
That one time I have to extract, transform and load a massive CSV file into a bunch of database entities and it was kinda slow…
The class had position based CSV bindings, loaded into beans and streamed from a pretty big CSV file (+10Gb):
public class CSVUserEntry {
@CsvBindByPosition(position = 0)
private String userId;
@CsvBindByPosition(position = 1)
private String username;
@CsvBindByPosition(position = 2)
private String deviceId;
@CsvBindByPosition(position = 3)
private String keyAlias;
@CsvBindByPosition(position = 4)
private String passcodeKeyAlias;
@CsvBindByPosition(position = 5)
private String confirmationId;
}
Then I opened the stream in generic way, with a simple and fluent interfaces of Java stream API:
import com.opencsv.bean.CsvToBean;
import com.opencsv.bean.CsvToBeanBuilder;
public Stream<T> openStreamReader(final String filename, final Class<T> clazz) throws IOException {
reader = new FileReader(Path.of(filename).toString());
final CsvToBean<T> csvReader = new CsvToBeanBuilder<T>(reader)
.withType(clazz)
.withSeparator(',')
.withIgnoreEmptyLine(true)
.withSkipLines(1) //skip header
.build();
return csvReader.stream();
}
The returned stream will be consumed by .forEach().
With that simple code things started going south. Application was suddenly consuming all the CPUs it could, memory usage went thought the roof, overall performance degraded and after several minutes we got OOM crashes with 5.5Gb heap dumps… welp. Quick investigation with Eclipse MAT showed me the problem.
Heap usage:
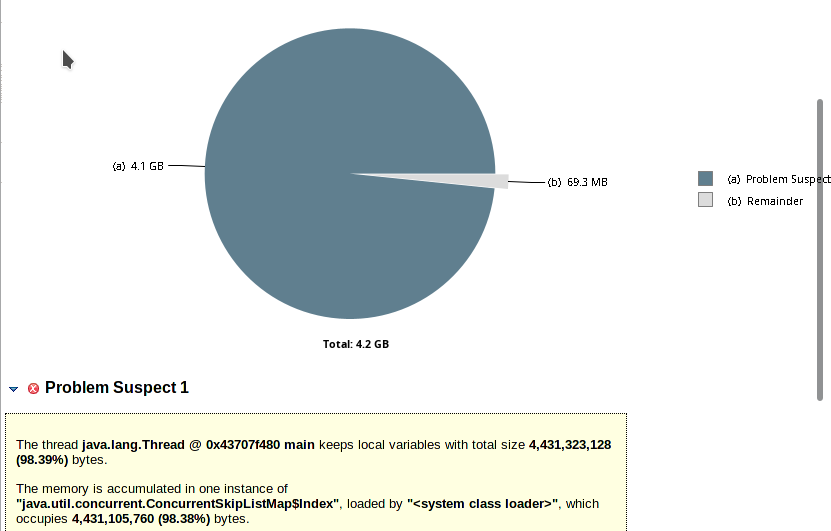
Thread allocations:
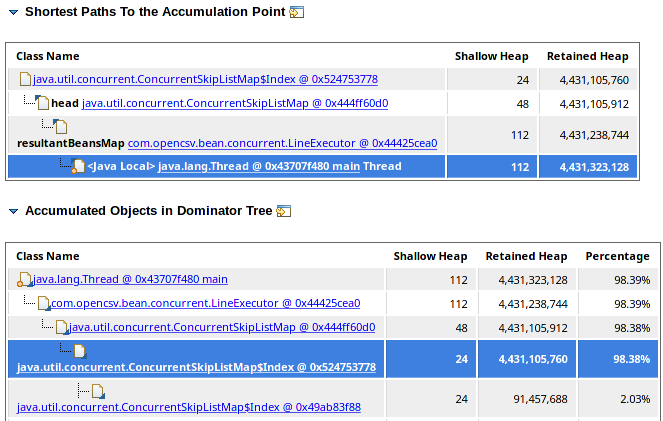
Now, that’s enough information, but let’s dig a bit deeper to see if I can easily fix it. I checked for references and path to get from top of the thread to my object:
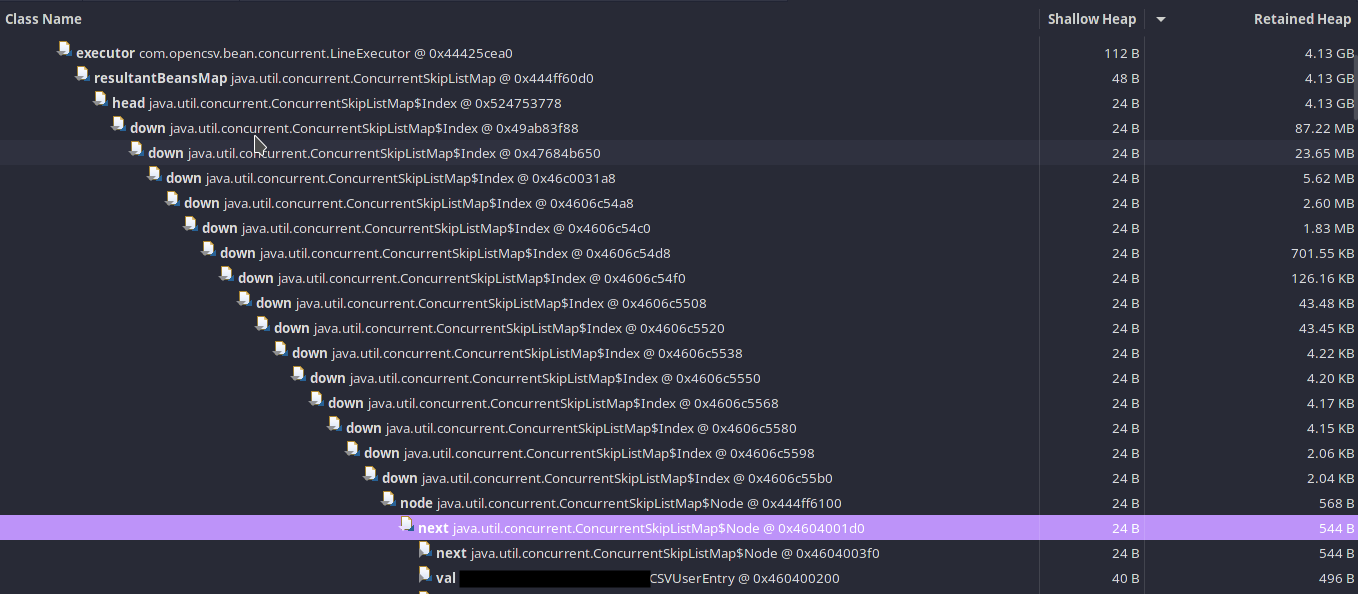
That’s an awful lot of ConcurrentSkipListMap references to get to a single bean.
I quickly looked at alternatives how to consume the CSV file without using Stream/Spliterator APIs. There is another method .iterator() which simply exposes Iterator<T>. Now, I’ll just compare implementation before trying it:
@Override
public Iterator<T> iterator() {
prepareToReadInput();
return new CsvToBeanIterator();
}
Yup, LGTM. I’m going to use this one to fix my memory leak. A few minutes later, memory usage dropped from ~13000Mb (yes, the JVM was started with -Xmx15500m) to stable 150Mb.